High Performance Computing Smooth(ed) Particle Hydrodynamics
The successor of miluphcuda targeting GPU cluster via CUDA aware MPI.
This repository implements a multi-GPU SPH & N-body (via Barnes-Hut) algorithm using C++11 and CUDA-aware MPI by combining already proven parallelization strategies and available implementations
- single-GPU version inspired/adopted from:
- multi-node (or rather multi-CPU) version inspired/adopted from:
- M. Griebel, S. Knapek, and G. Zumbusch. Numerical Simulation in Molecular Dynamics: Numerics, Algorithms, Parallelization, Applications. 1st. Springer Pub- lishing Company, Incorporated, 2010. isbn: 3642087760
with new ideas and parallelization strategies.
- for a versatile single-GPU implementation refer to miluphcuda
- for a multi-CPU implementation (self-gravity via Barnes-Hut only) refer to jammartin/ParaLoBstar
See also:
- milupHPC API documentation (Doxygen)
- Prerequisites.md: for instructions to install the dependencies
- Compilation.md: for instructions to compile the code
- GettingStarted.md: for getting started, including running some test cases
- Plummer gravity-only test case (README)
- Taylor-von Neumann-Sedov blast wave SPH-only test case (../testcases/sedov/README.md "README")
- Postprocessing.md: for information regarding postprocessing
- H5Renderer for basic rendering (../H5Renderer/README.md "README")
- Debugging.md: for information regarding debugging
Repository content:
| Directory | Description |
|---|---|
| src/ & include/ | **actual multi-GPU SPH & Barnes-Hut implementation** |
| bin/ | binary to be executed, compile via make| | build/ | build files, created by make | | debug/ | debugging with gdb, lldb, cuda gdb (README) | | config/ | config files for settings (.info) and material parameters (.cfg) (README) | | testcases/ | test cases including Plummer and Sedov (README) | | cluster/ | information to dispatch simulation on clusters using queing systems (README) | | postprocessing/ | postprocessing scripts (README) | | H5Renderer/ | H5Renderer implementation: basic Renderer (2D) (README) | | utilities/ | utilities e.g. counting lines of code (README) | | doc/ | create Doxygen documentation (README) | | documents/ | several documents including files for README, instructions, notes, ... | | images/ | images for MD files, ... |
Parallelization/Implementation
- Parallelization embraces both
- multi-node parallelization via message-passing (MPI) and
- single-node parallelization for **GPU**s via CUDA
implemented using C++ and CUDA-aware MPI.

Implementation details
| Directory | File | Description |
|---|---|---|
| **./** | include/ & src/ directory | |
| main.cpp | main: setting CUDA device, config parsing, loading parameters/settings, integrator selection, start of simulation | |
| *miluphpc.h/cpp* | abstract base class defining largest reoccuring part of the simulation (right hand side) and assorted high level functionalities | |
| particles.cuh/cu | particle class (SoA) and reduced particle class: particle attributes like mass, position, velocity, density, ... | |
| particle_handler.h/cpp | handler class for particle class including memory allocation and copy mechanisms | |
| simulation_time.cuh/cu | simulation time class: start & end time, time step, ... | |
| *simulation_time_handler.cpp* | handler for simulation time class including memory allocation and copy mechanisms | |
| device_rhs.cuh/cu | CUDA kernels for resetting arrays/variables (in between right hand sides) | |
| helper.cuh/cu | buffer class and sorting algorithms (based on CUDA cub) | |
| *helper_handler.h/cpp* | buffer class handler including memory allocation and copy mechanisms | |
| subdomain_key_tree/ | (parallel) tree related functionalities including tree construction and domain decomposition | |
| tree.cuh/cu | (local) tree class and CUDA kernels for tree construction | |
| tree_handler.h/cpp | (local) tree class handler including memory allocation and kernel execution wrapper | |
| *subdomain.cuh/cu* | (parallel) tree structures including domain decomposition, SFC keys, ... | |
| *subdomain_handler.h/cpp* | (parallel) tree handling including memory allocation and kernel execution | |
| gravity/ | gravity related functionalities according to the Barnes-Hut method | |
| gravity.cuh/cu | gravity related CUDA kernels according to the Barnes-Hut method | |
| sph/ | Smoothed Particle Hydrodynamics (SPH) related functionalities | |
| *kernel.cuh/cu* | SPH smoothing kernels | |
| kernel_handler.cuh/cu | SPH smoothing kernels wrapper | |
| *sph.cuh/cu* | fixed radius near neighbor search (FRNN) and multi-node SPH | |
| density.cuh/cu | SPH density | |
| *pressure.cuh/cu* | SPH pressure | |
| soundspeed.cuh/cu | SPH speed of sound | |
| *internal_forces.cuh/cu* | SPH internal forces | |
| *stress.cuh/cu* | SPH stress (not fully implemented yet) | |
| *viscosity.cuh/cu* | SPH viscosity (not fully implemented yet) | |
| materials/ | material attributes (as needed for SPH) | |
| material.cuh/cu | material attributes class | |
| material_handler.cuh/cpp | material attributes handler class including loading from *.cfg* file | |
| integrator/ | child classes for miluphpc implementing integrate() | |
| device_explicit_euler.cuh/cu | explicit Euler integrator device implementations | |
| *explicit_euler.h/cpp* | explicit Euler integrator logic and flow | |
| *device_leapfrog.cuh/cu* | leapfrog integrator device implementations | |
| *leapfrog.h/cpp* | leapforg integrator logic and flow | |
| *device_predictor_corrector_euler.cuh/cu* | predictor-corrector Euler integrator device implementations | |
| *predictor_corrector_euler.h/cpp* | predictor-corrector Euler integrator logic and flow | |
| processing/ | removing particles that moved to far from simulation center, ... | |
| kernels.cuh/cu | removing particles that moved to far from simulation center based on a sphere/cuboid | |
| utils/ | C++ utilites like config parsing, logging, profiling, timing, ... | |
| config_parser.h/cpp | config parser based on cxxopts | |
| h5profiler.h/cpp | HDF5 profiler based on HighFive | |
| *logger.h/cpp* | Logger class and functionalities (taking MPI ranks into account) | |
| *timer.h/cpp* | timing events based on MPI timer | |
| cuda_utils/ | CUDA utilities including wrappers, execution policy and math kernels | |
| cuda_launcher.cuh/cu | CUDA Kernel wrapper and execution policy | |
| cuda_runtime.h/cpp | thin CUDA API wrapper | |
| cuda_utilities.cuh/cu | utilities for CUDA including simple kernels, assertions, ... | |
| linalg.cuh/cu | linear algebra CUDA kernels |
- pre-processing (inititial particle distribution, ...)
- preparation tasks like
- initializing the MPI and CUDA environment
- reading the initial particle distribution
- memory allocation, ...
- the actual simulation in dependence of the used integration scheme
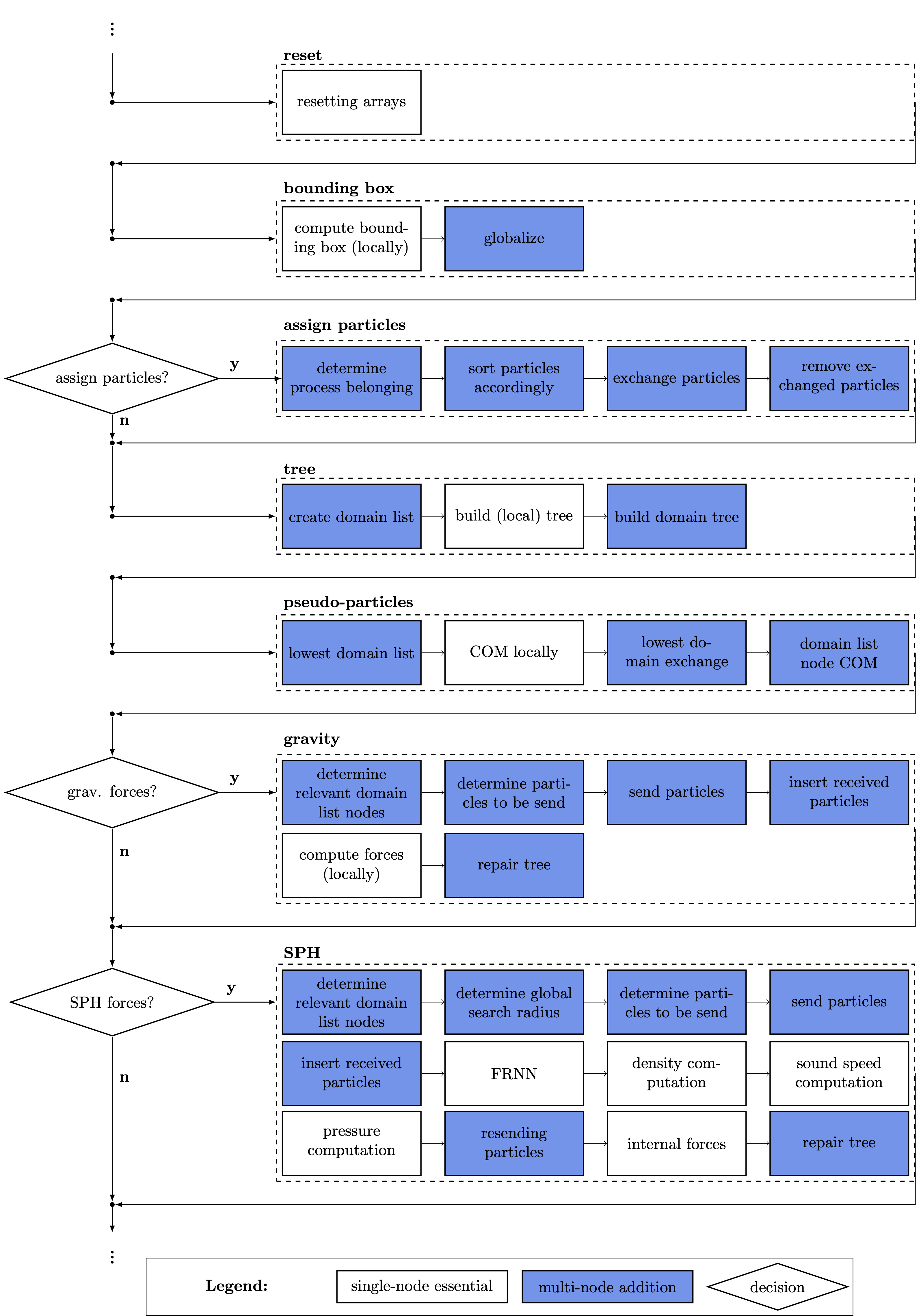
- encapsulated in the right-hand-side (as depicted in the following picture)
- advancing the particles
- encapsulated in the right-hand-side (as depicted in the following picture)
- post-processing
- ...
Prerequisites/Dependencies
For more information and instructions refer to Prerequisites.md
| library | licence | usage | link |
|---|---|---|---|
| GNU | GPLv3+ | compiler | gnu.org |
| OpenMPI | BSD 3-Clause | compiler, MPI Implementation | open-mpi.org |
| CUDA | CUDA Toolkit End User License Agreement | compiler, CUDA Toolkit and API | developer.nvidia.com |
| CUDA cub | BSD 3-Clause "New" or "Revised" License | device wide parallel primitives | github.com/NVIDIA/cub |
| HDF5 | HDF5 License (BSD-Style) | parallel HDF5 for I/O operations | hdf5group.org |
| HighFive | Boost Software License 1.0 | C++ wrapper for parallel HDF5 | github.com/BlueBrain/HighFive |
| Boost | Boost Software License 1.0 | config file parsing, C++ wrapper for MPI | boost.org |
| cxxopts | MIT license | command line argument parsing | github.com/jarro2783/cxxopts |
| libconfig | LGPL-2.1 | material config parsing | github.io/libconfig |
- in general there is no need for the usage of the GNU compiler and OpenMPI as MPI implementation, as long as a proper C++ compiler as well as MPI implementation (CUDA-aware) are available and corresponding changes in the Makefile are done
Usage
- you need to provide an appropriate H5 file as initial (particle) distribution
- see e.g. GitHub: ParticleDistributor
- build/compile using the Makefile via:
make- for debug:
make debug- using cuda-gdb:
./debug/cuda_debug.sh
- using cuda-gdb:
- for single-precision:
make single-precision(default: double-precision)
- for debug:
- run via **
mpirun -np <np> <binary> -n <#output files> -f <input hdf5 file> -C <config file> -m <material-config>**<binary>withinbin/e.g.bin/runner<input hdf5 file>: appropriate HDF5 file as initial (particle) distribution<config file>: configurations<material-config>: material configurations- as well as correct preprocessor directives:
include/parameter.h
- clean via:
make clean,make cleaner - rebuild via:
make remake
Preprocessor directives: parameter.h
Input HDF5 file
- for gravity only
- provide mass "m", position "x" and velocity "v"
- with SPH provide (at least)
- provide mass "m", material identifier "materialId", internal energy "u", position "x" and velocity "v"
Config file
Material config file
Command line arguments
./bin/runner -hgives help:
Samples/Validation
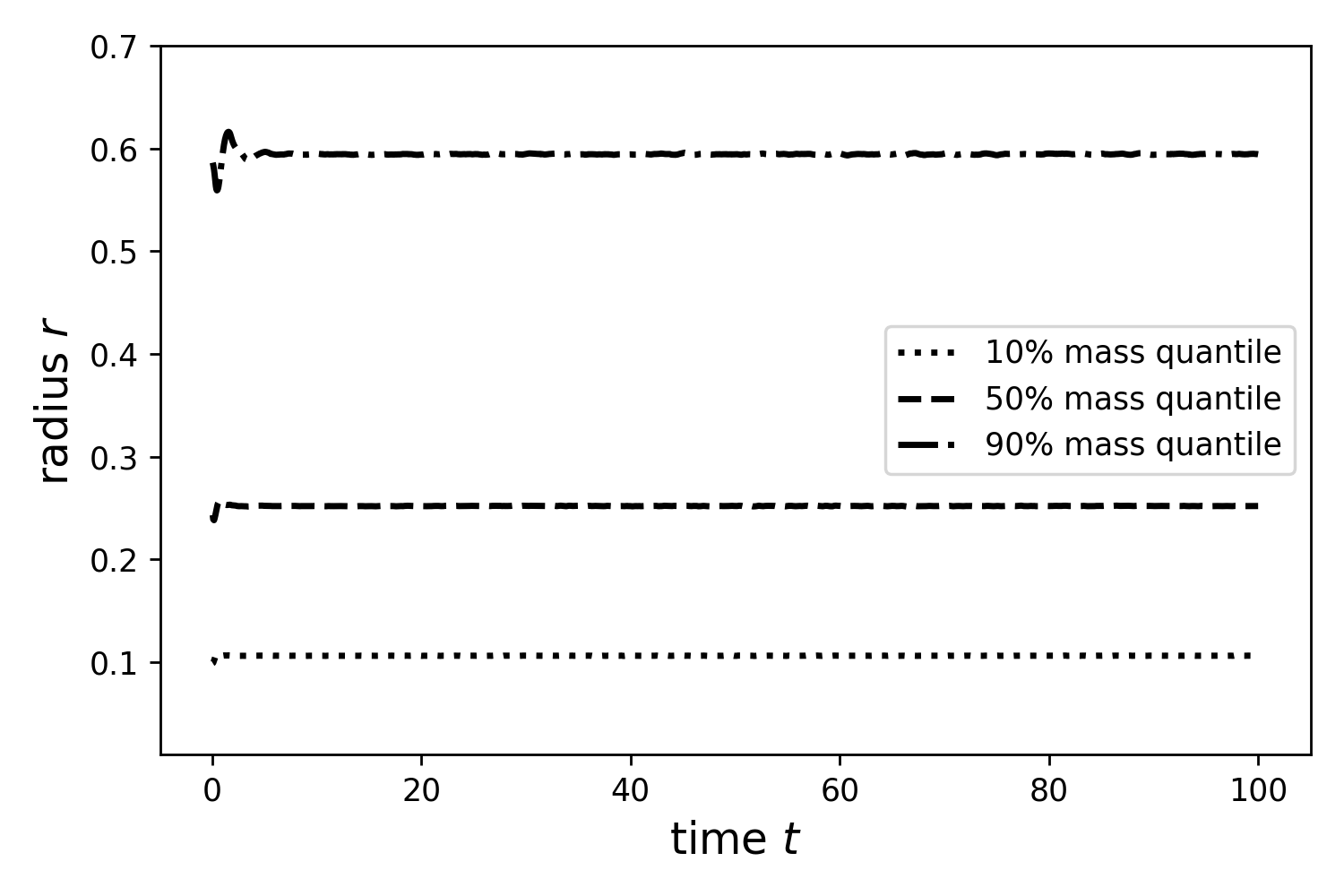
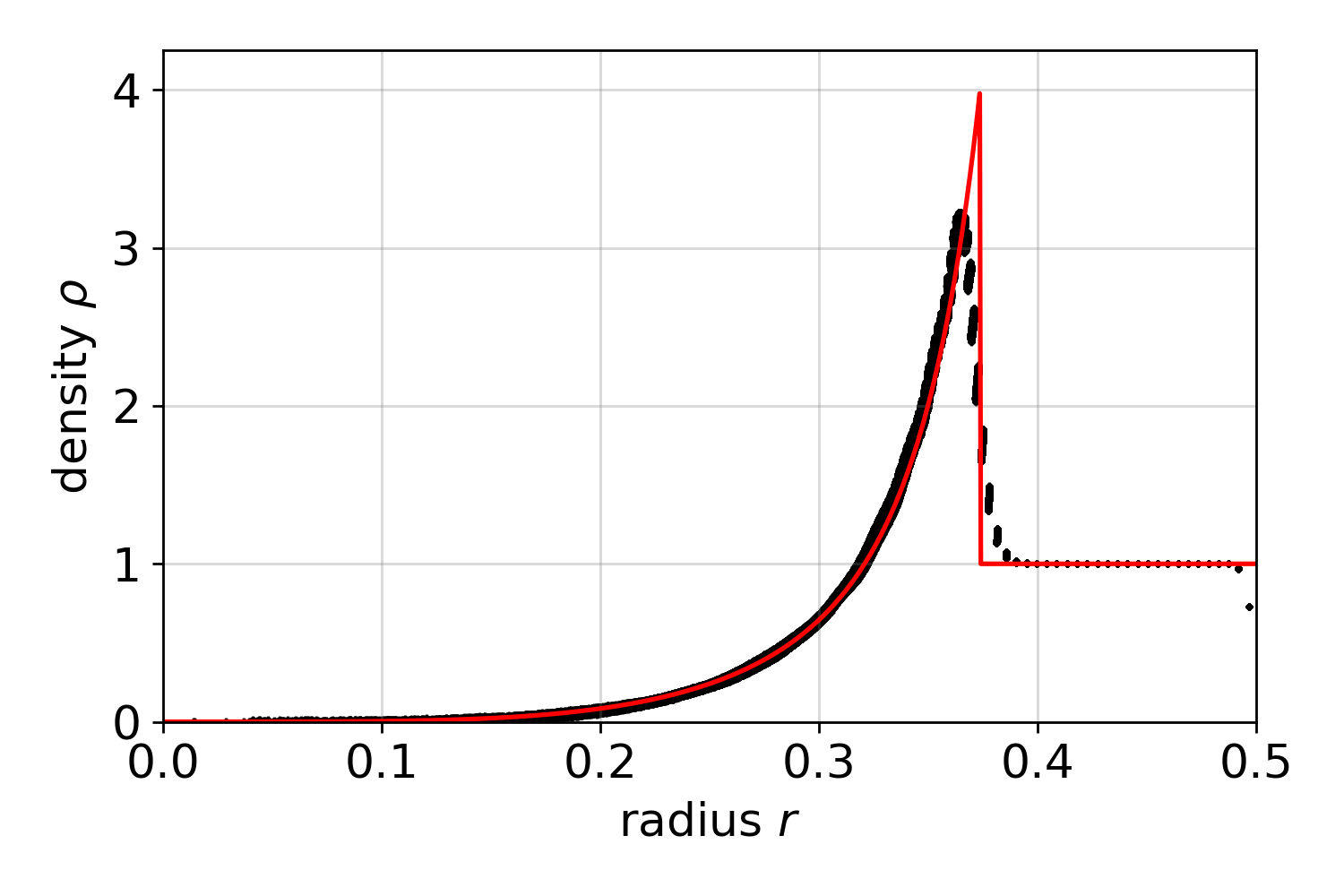
The code validation comprises the correctness of dispatched simulation on one GPU and multiple GPUs, whereas identical simulation on one and multiple GPUs are not mandatorily bitwise-identical. By suitable choice of compiler flags and in dependence of the used architecture this is in principle attainable. However, this is generally not useful to apply for performance reasons and therefore at this point not presupposed. Amongst others, three test cases were used for validating the implementation:
- the Plummer test case is a gravity-only test case
- the Taylor–von Neumann–Sedov blast wave test case is a pure hydrodynamical SPH test case
- the isothermal collapse test case self-gravitating SPH test case utilizing almost all implemented features
each color represents a process, thus a GPU
Plummer
- refer to this testcase (README)
- Plummer model: four GPUs with dynamic load balancing every 10th step (top: lebesgue, bottom: hilbert)
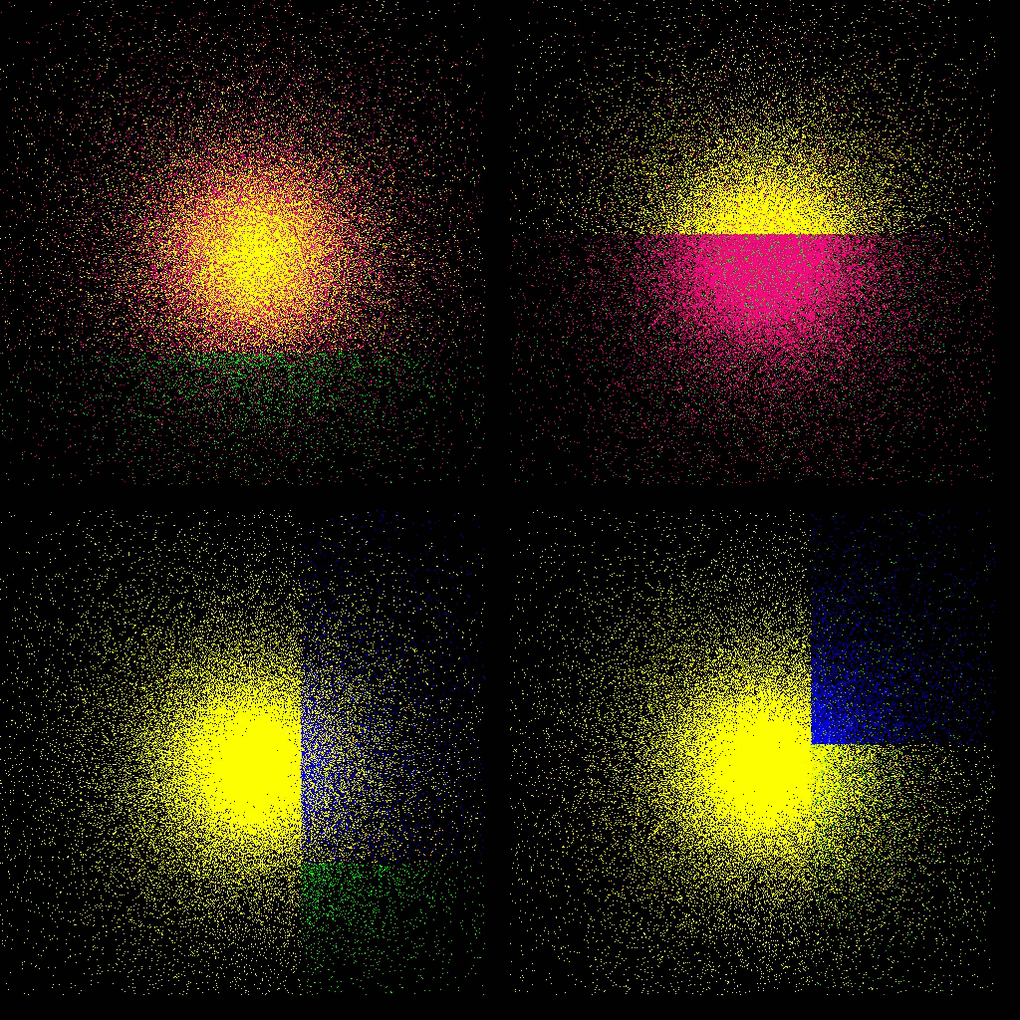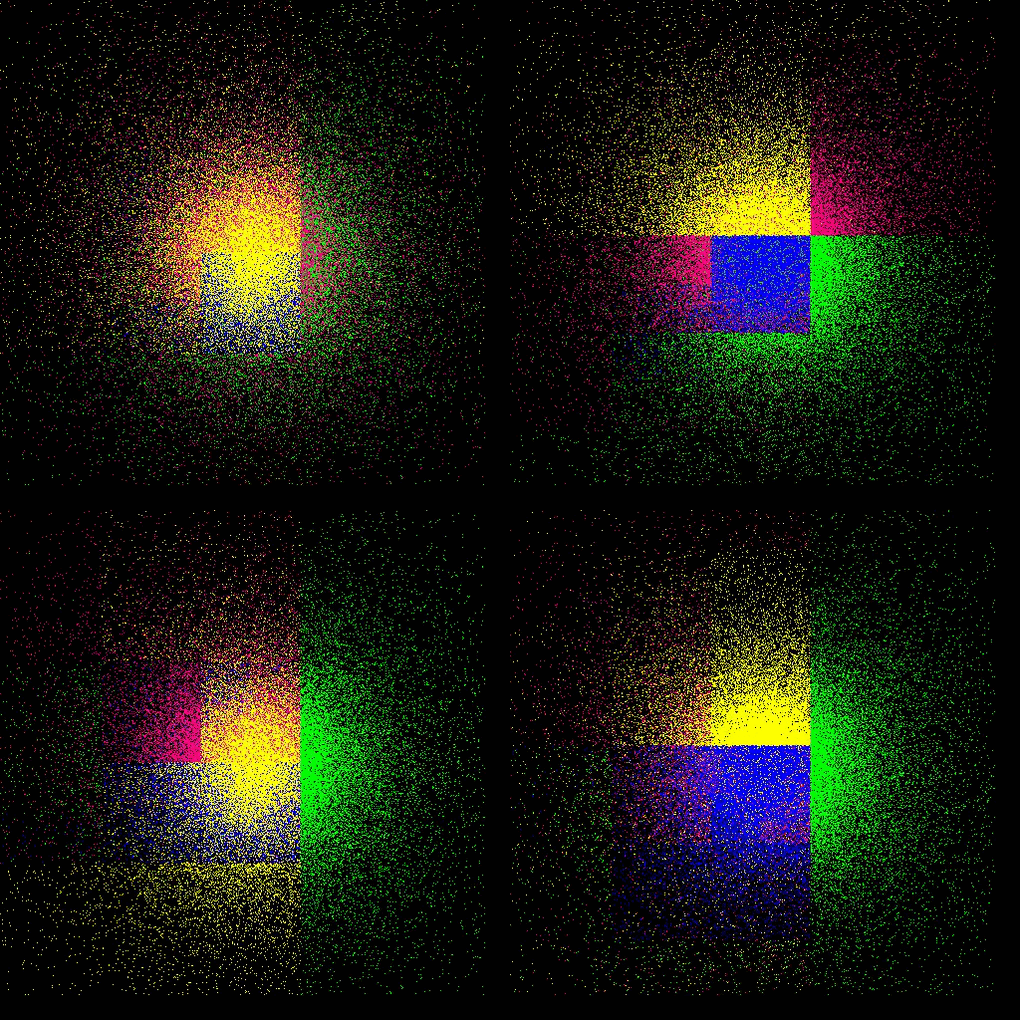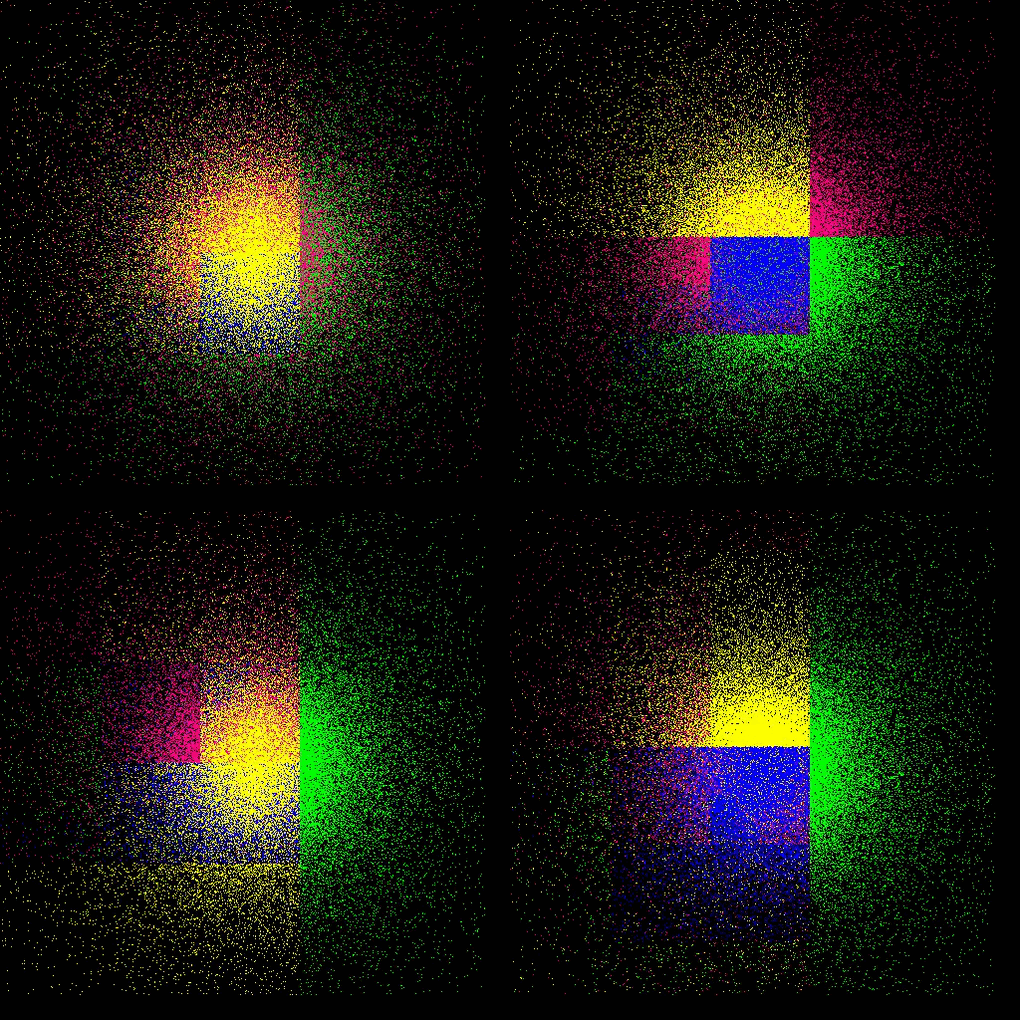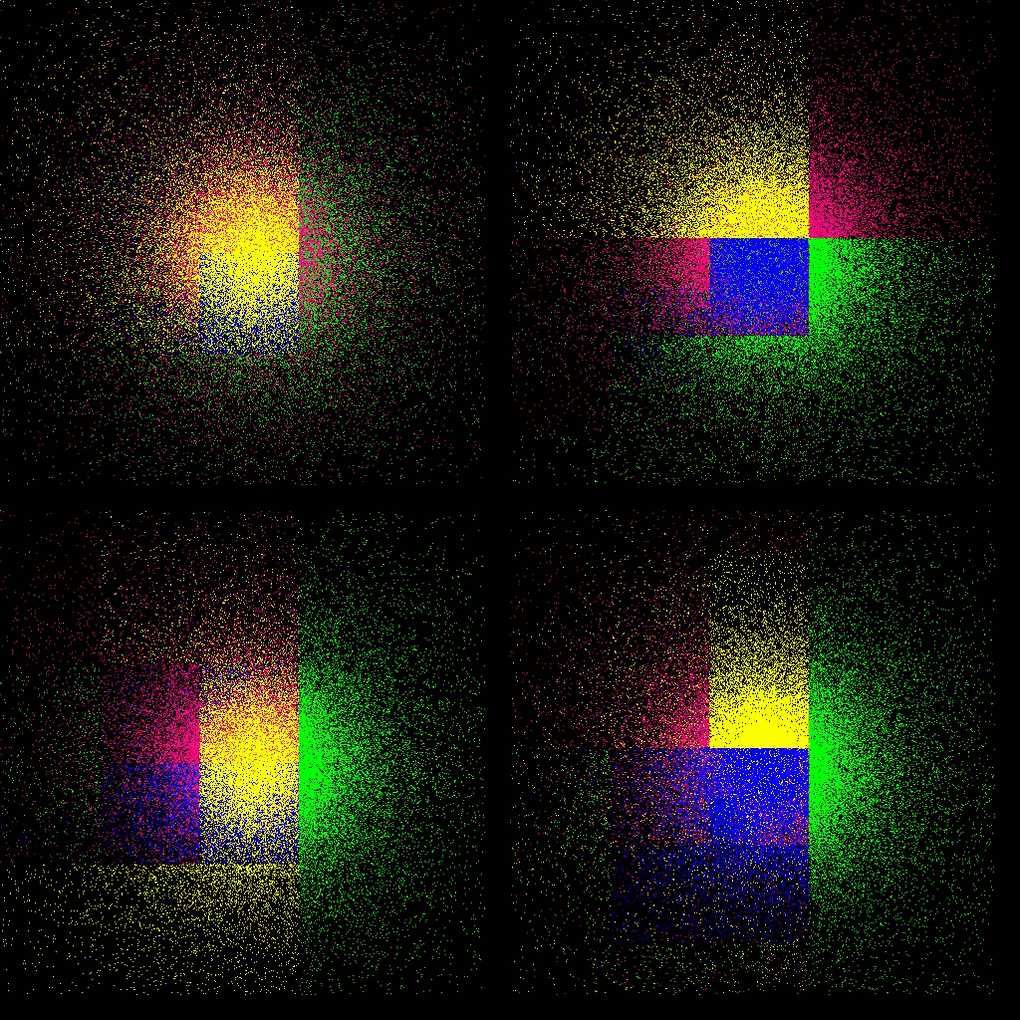
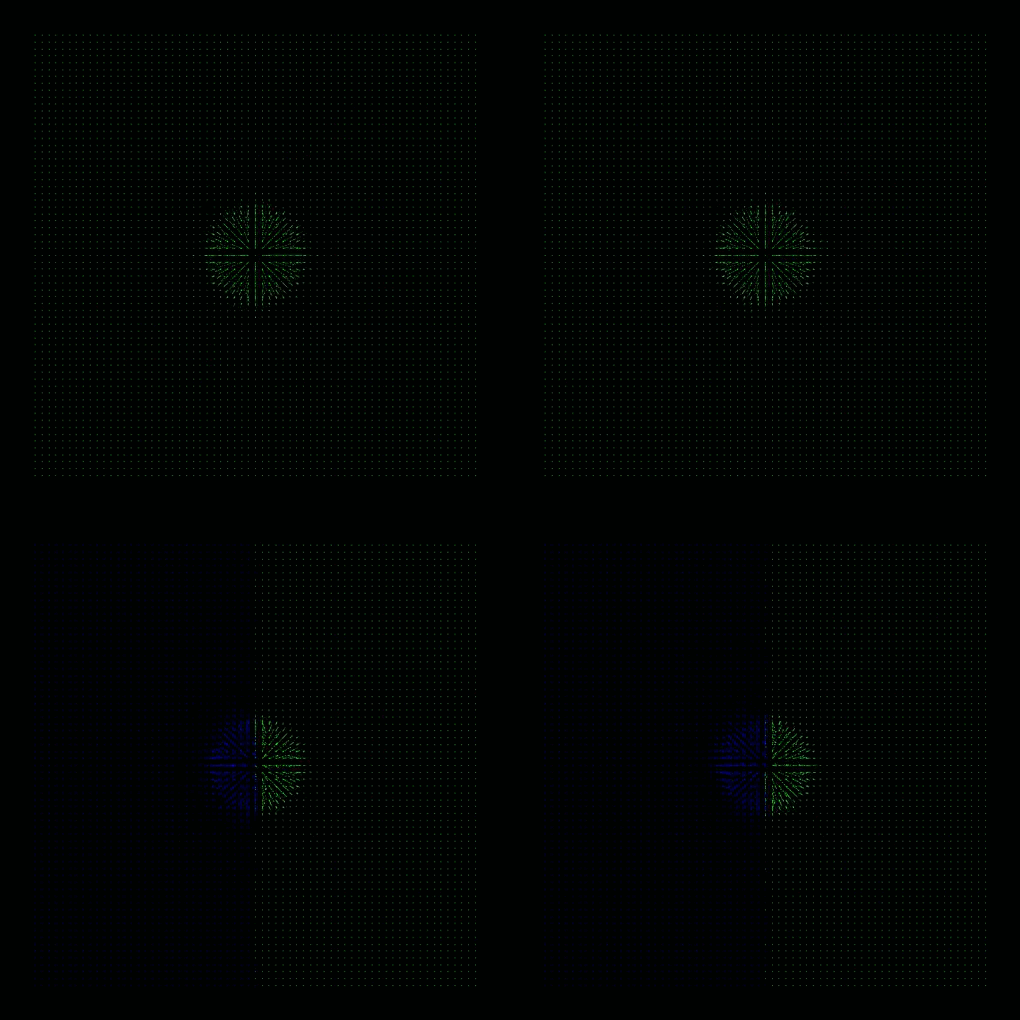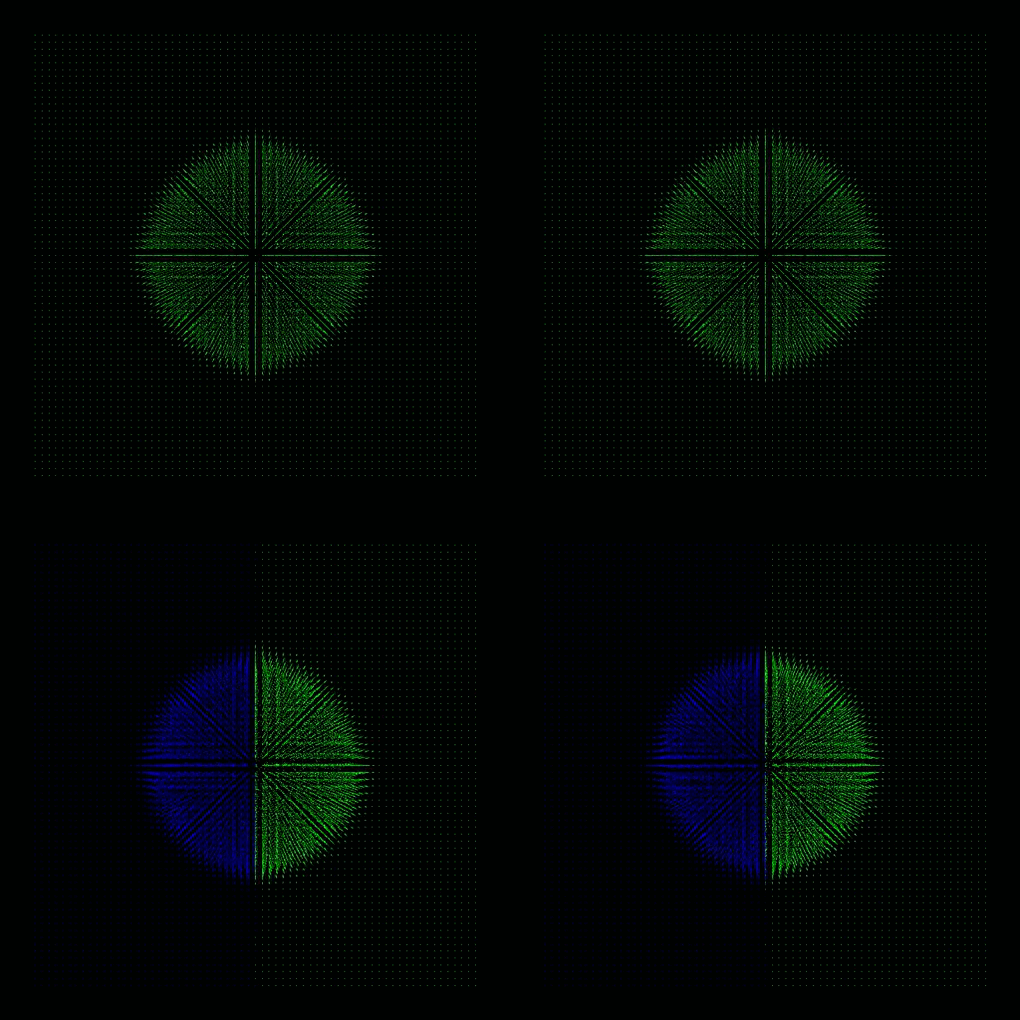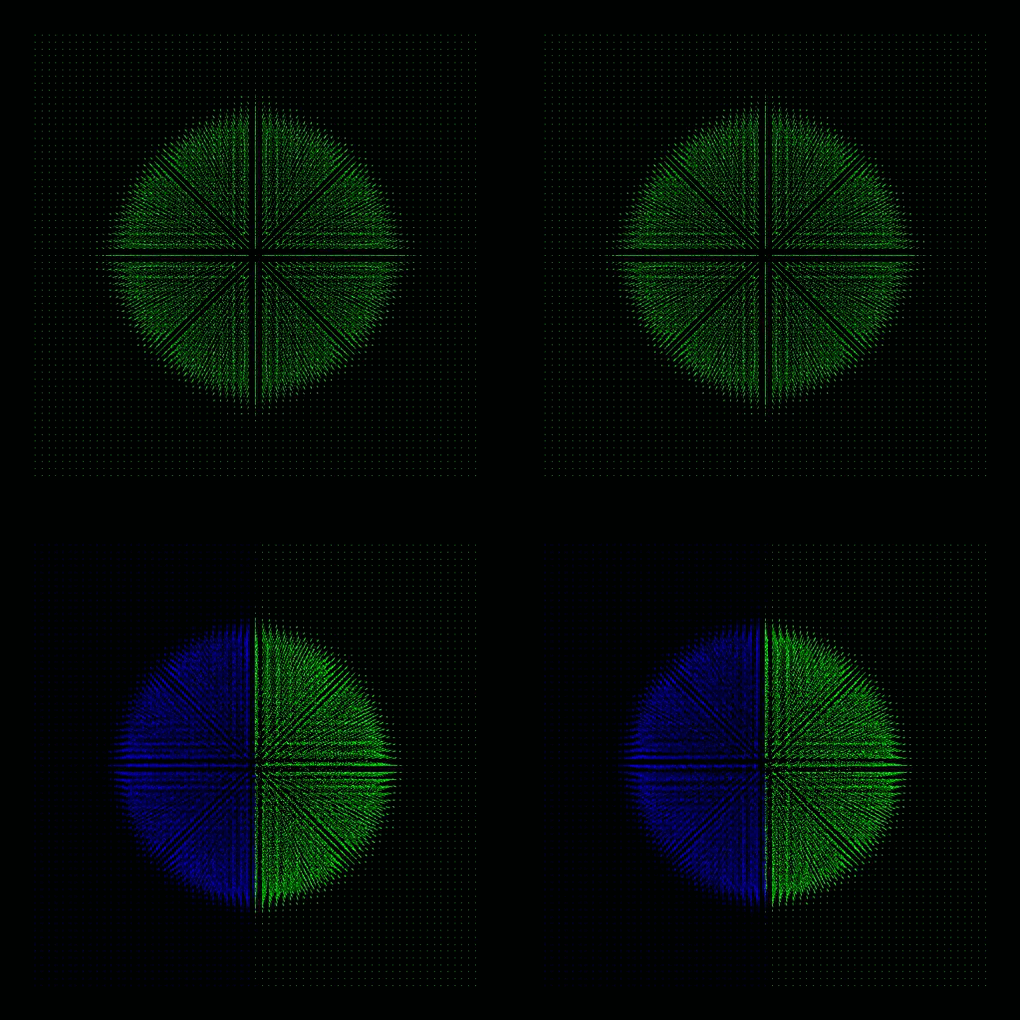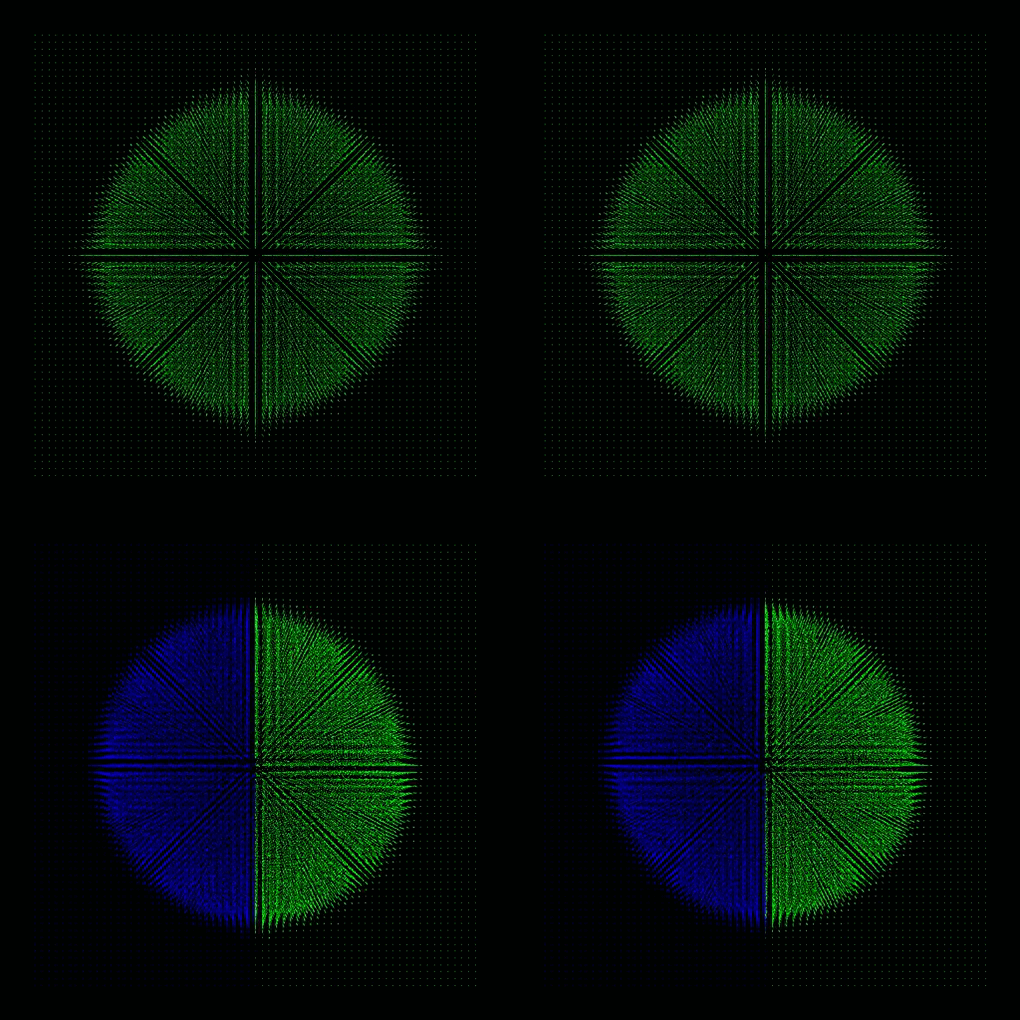
Taylor–von Neumann–Sedov blast wave
- refer to this testcase (README)
- Sedov explosion: one and two GPUs
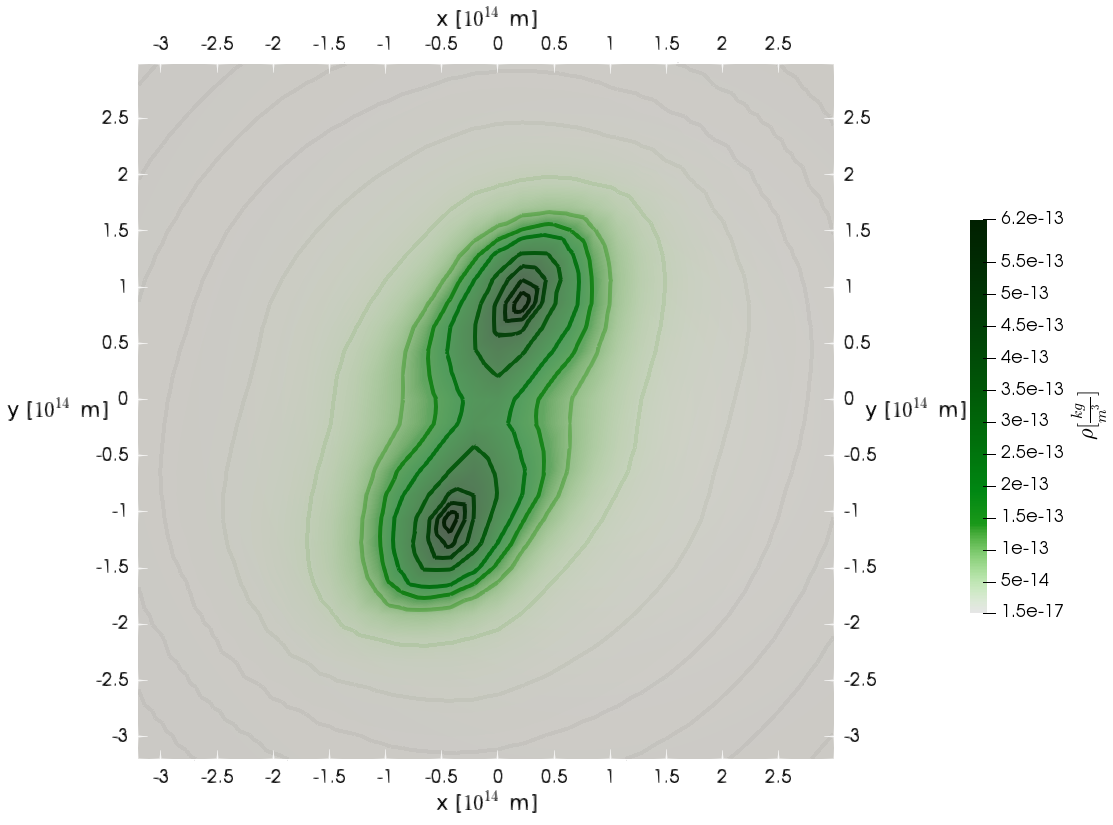
Boss-Bodenheimer: Isothermal collapse
- Boss-Bodenheimer: isothermal collapse
- one and two GPUs
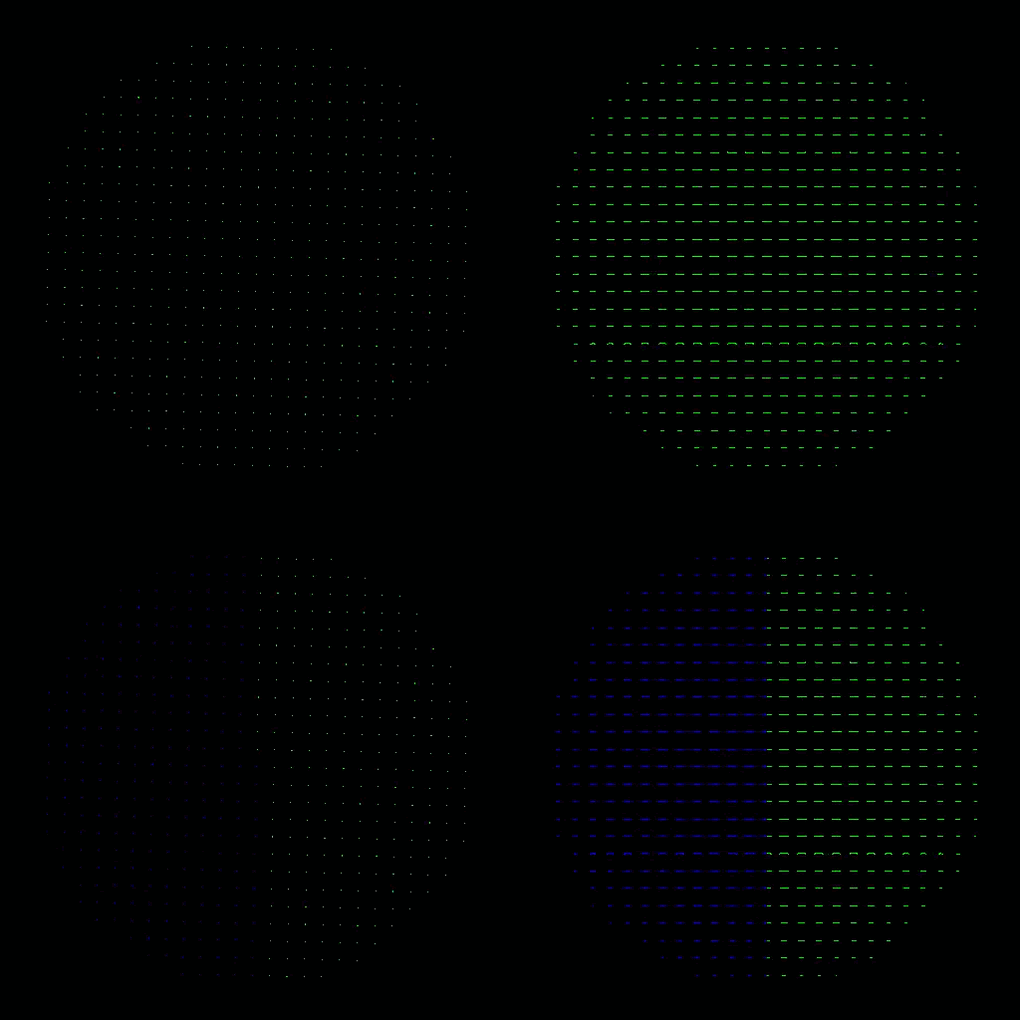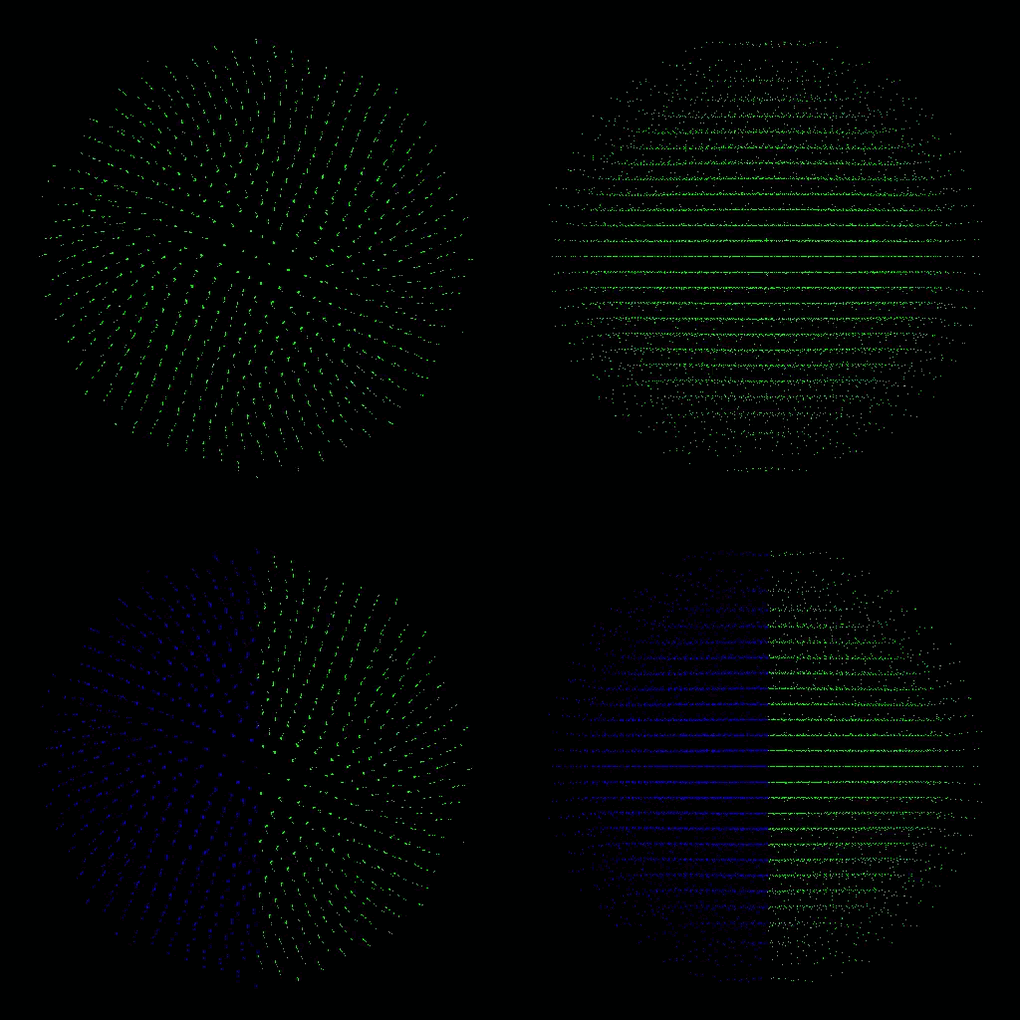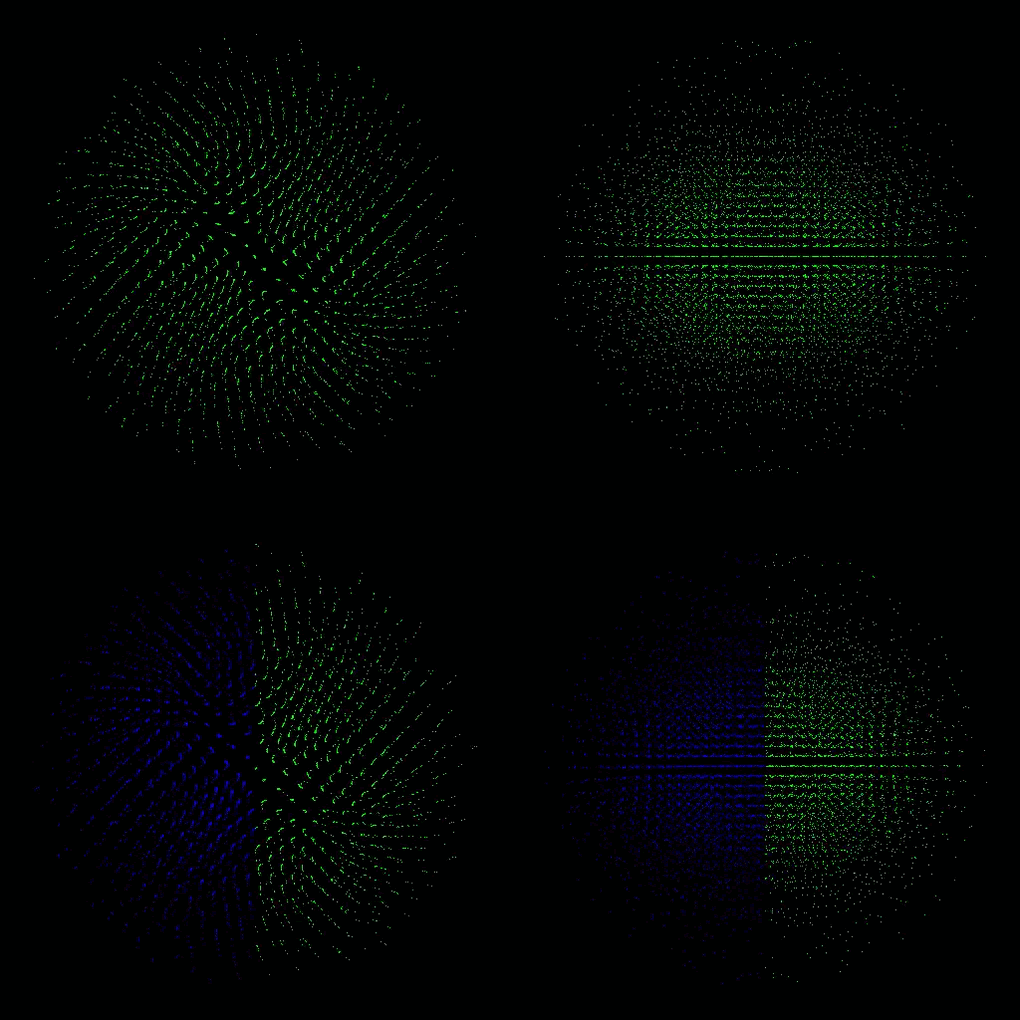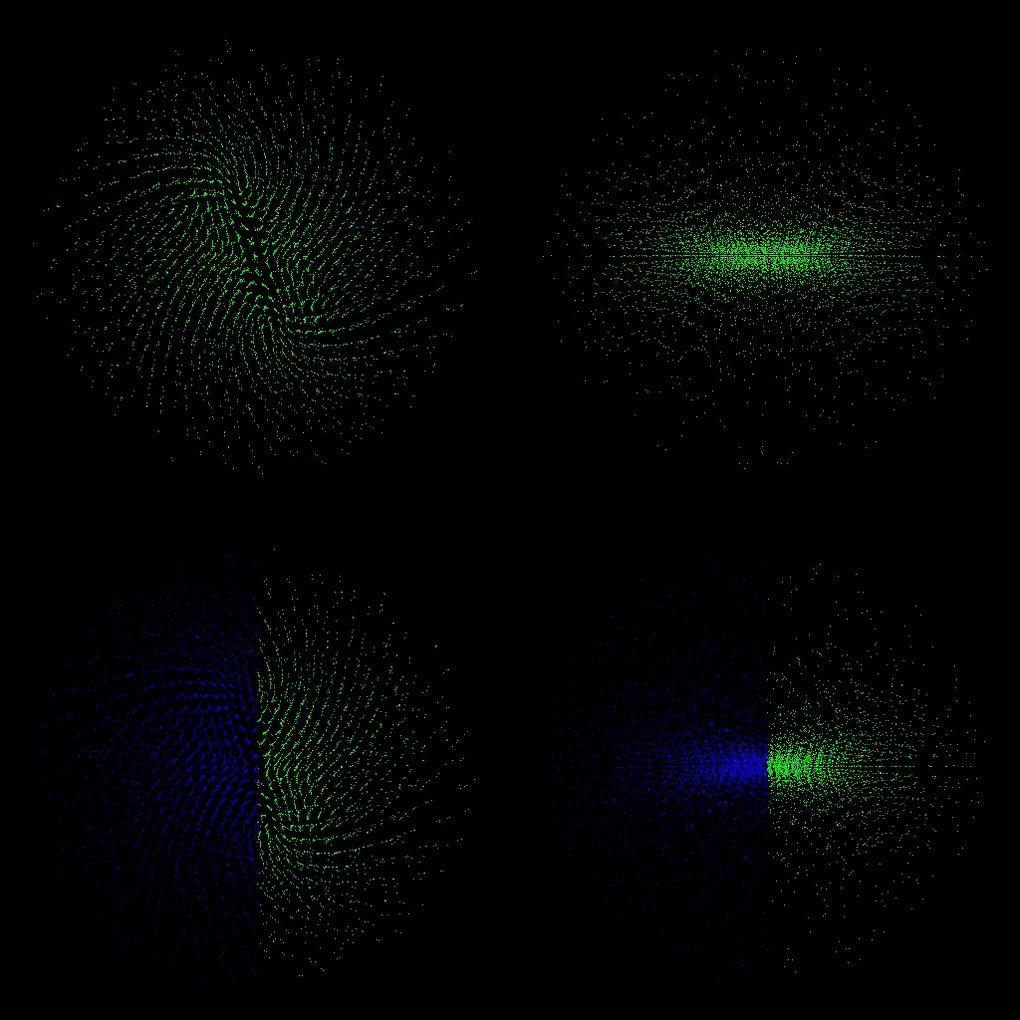
milupHPC - milupHPC
Generated on Wed Aug 31 2022 12:16:53 by Doxygen 1.9.3